1. Multicore Computing
In the past, software developers
benefitted from the continual performance gains of new hardware in
single-core computers. If your application was slow, just wait—it would
soon run faster because of advances in hardware performance. Your
application simply rode the wave of better performance. However, you can
no longer depend on consistent hardware advancements to assure
better-performing applications!
As performance improvement in
new generations of processor cores has slowed, you now benefit from the
availability of multicore architecture. This allows developers to
continue to realize increases in performance and to harness that speed
in their applications.
At the moment, dual-core
and quad-core machines are the de facto standard. In North America and
other regions, you probably cannot (and would not want to) purchase a
single-core desktop computer at a local computer store today.
Single-core computers have
constraints that prevent the continuation of the performance gains that
were possible in the past. The primary constraint is the correlation of
processor speed and heat. As processor speed increases, heat increases
disproportionally. This places a practical threshold on processor speed.
Solutions have not been found to significantly increase computing power
without the heat penalty. Multicore architecture is an alternative,
where multiple processor cores share a chip die. The additional cores
provide more computing power without the heat problem. In a parallel
application, you can leverage the multicore architecture for potential
performance gains without a corresponding heat penalty.
Multicore personal
computers have changed the computing landscape. Until recently,
single-core computers have been the most prevalent architecture for
personal computers. But that is changing rapidly and represents nothing
short of the next evolutionary step in computer architecture for
personal computers. The combination of multicore architecture and
parallel programming will propagate Moore’s Law into the foreseeable
future.
With
the advent of techniques such as Hyper-Threading Technology from Intel,
each physical core becomes two or potentially more virtual cores. For
example, a machine with four physical cores appears to have eight
logical cores. The distinction between physical and logical cores is
transparent to developers and users. In the next 10 years, you can
expect the number of both physical and virtual processor cores in a
standard personal computer to increase significantly.
1.1. Multiple Instruction Streams/Multiple Data Streams
In 1966, Michael Flynn
proposed a taxonomy to describe the relationship between concurrent
instruction and data streams for various hardware architectures. This
taxonomy, which became known as Flynn’s taxonomy, has these categories:
SISD (Single Instruction Stream/Single Data Stream)
This model has a single instruction stream and data stream and
describes the architecture of a computer with a single-core processor.
SIMD (Single Instruction Stream/Multiple Data Streams)
This model has a single instruction stream and multiple data streams.
The model applies the instruction stream to each of the data streams.
Instances of the same instruction stream can run in parallel on multiple
processor cores, servicing different data streams. For example, SIMD is
helpful when applying the same algorithm to multiple input values.
MISD (Multiple Instruction Streams/Single Data Stream)
This model has multiple instruction streams and a single data stream
and can apply multiple parallel operations to a single data source. For
example, this model could be used for running various decryption
routines on a single data source.
MIMD (Multiple Instruction Streams/Multiple Data Streams)
This model has both multiple instruction streams and multiple data
streams. On a multicore computer, each instruction stream runs on a
separate processor with independent data. This is the current model for
multicore personal computers.
The MIMD model can be refined
further as either Multiple Program/Multiple Data (MPMD) or Single
Program/Multiple Data (SPMD). Within the MPMD subcategory, a different
process executes independently on each processor. For SPMD, the process
is decomposed into separate tasks, each of which represents a different
location in the program. The tasks execute on separate processor cores.
This is the prevailing architecture for multicore personal computers
today.
The following table plots Flynn’s taxonomy.
| Flynn’s Taxonomy | Single Data Stream | Multiple Data Streams |
|---|
| Single Instruction Stream | SISD | SIMD |
| Multiple Instruction Streams | MISD | MIMD |
Additional information about Flynn’s taxonomy is available at Wikipedia: http://en.wikipedia.org/wiki/Flynn%27s_taxonomy.
1.2. Multithreading
Threads represent actions
in your program. A process itself does nothing; instead, it hosts the
resources consumed by the running application, such as the heap and the
stack. A thread is one possible path of execution in the application.
Threads can perform independent tasks or cooperate on an operation with
related tasks.
Parallel applications are
also concurrent. However, not all concurrent applications are parallel.
Concurrent applications can run on a single core, whereas parallel
execution requires multiple cores. The reason behind this distinction is
called interleaving.
When multiple threads run concurrently on a single-processor computer,
the Windows operating system interleaves the threads in a round-robin
fashion, based on thread priority and other factors. In this manner, the
processor is shared between several threads. You can consider this as logical parallelism.
With physical parallelism, there are multiple cores where work is
decomposed into tasks and executed in parallel on separate processor
cores.
Threads are preempted
when interrupted for another thread. At that time, the running thread
yields execution to the next thread. In this manner, threads are
interleaved on a single processor. When a thread is preempted, the
operating system preserves the state of the running thread and loads the
state of the next thread, which is then able to execute. Exchanging
running threads on a processor triggers a context switch
and a transition between kernel and user mode. Context switches are
expensive, so reducing the number of context switches is important to
improving performance.
Threads are preempted for several reasons:
A higher priority thread needs to run.
Execution time exceeds a quantum.
An input-output request is received.
The thread voluntarily yields the processor.
The thread is blocked on a synchronization object.
Even on a single-processor machine, there are advantages to concurrent execution:
Multitasking
A responsive user interface
Asynchronous input-output
Improved graphics rendering
Parallel
execution requires multiple cores so that threads can execute in
parallel without interleaving. Ideally, you want to have one thread for
each available processor. However, that is not always possible. Oversubscription
occurs when the number of threads exceeds the number of available
processors. When this happens, interleaving occurs for the threads
sharing a processor. Conversely, undersubscription
occurs when there are fewer threads than available processors. When
this happens, you have idle processors and less-than-optimum CPU
utilization. Of course, the goal is maximum CPU utilization while
balancing the potential performance degradation of oversubscription or
undersubscription.
As mentioned earlier,
context switches adversely affect performance. However, some context
switches are more expensive than others; one of the more expensive ones
is a cross-core context switch. A thread can run on a dedicated
processor or across processors. Threads serviced by a single processor
have processor affinity,
which is more efficient. Preempting and scheduling a thread on another
processor core causes cache misses, access to local memory as the result
of cache misses, and excess context switches. In aggregate, this is
called a cross-core context switch.
1.3. Synchronization
Multithreading involves
more than creating multiple threads. The steps required to start a
thread are relatively simple. Managing those threads for a thread-safe
application is more of a challenge. Synchronization is the most common
tool used to create a thread-safe environment. Even single-threaded
applications use synchronization on occasion. For example, a
single-threaded application might synchronize on kernel-mode resources,
which are shareable across processes. However, synchronization is more
common in multithreaded applications where both kernel-mode and
user-mode resources might experience contention. Shared data is a second
reason for contention between multiple threads and the requirement for
synchronization.
Most synchronization
is accomplished with synchronization objects. There are dedicated
synchronization objects, such as mutexes, semaphores, and events.
General-purpose objects that are also available for synchronization
include processes, threads, and registry keys. For example, you can
synchronize on whether a thread has finished executing. Most
synchronization objects are kernel objects, and their use requires a
context switch. Lightweight synchronization objects, such as critical
sections, are user-mode objects that avoid expensive context switches.
In the .NET Framework, the lock statement and the Monitor type are wrappers for native critical sections.
Contention
occurs when a thread cannot obtain a synchronization object or access
shared data for some period of time. The thread typically blocks until
the entity is available. When contention is short, the associated
overhead for synchronization is relatively costly. If short contention
is the pattern, such overhead can become nontrivial. In this scenario,
an alternative to blocking is spinning. Applications have the option to spin in user mode, consuming CPU
cycles but avoiding a kernel-mode switch. After a short while, the
thread can reattempt to acquire the shared resource. If the contention
is short, you can successfully acquire the resource on the second
attempt to avoid blocking and a related context switch. Spinning for
synchronization is considered lightweight synchronization, and Microsoft
has added types such as the SpinWait
structure to the .NET Framework for this purpose. For example, spinning
constructs are used in many of the concurrent collections in the System.Collections.Concurrent namespace to create thread-safe and lock-free collections.
Most parallel applications rely
on some degree of synchronization. Developers often consider
synchronization a necessary evil. Overuse of synchronization is
unfortunate, because most parallel programs perform best when running in
parallel
with no impediments. Serializing a parallel application through
synchronization is contrary to the overall goal. In fact, the speed
improvement potential of a parallel application is limited by the
proportion of the application that runs sequentially. For example, when
40 percent of an application executes sequentially, the maximum possible
speed improvement in theory is 60 percent. Most parallel applications
start with minimal synchronization. However, synchronization is often
the preferred resolution to any problem. In this way, synchronization
spreads—like moss on a tree—quickly. In extreme circumstances, the
result is a complex sequential application that for some reason has
multiple threads. In your own programs, make an effort to keep parallel
applications parallel.
2. Speedup
Speedup
is the expected performance benefit from running an application on a
multicore versus a single-core machine. When speedup is measured,
single-core machine performance is the baseline. For example, assume
that the duration of an application on a single-core machine is six
hours. The duration is reduced to three hours when the application runs
on a quad machine. The speedup is 2—(6/3)—in other words, the
application is twice as fast.
You might expect that an
application running on a single-core machine would run twice as quickly
on a dual-core machine, and that a quad-core machine would run the
application four times as fast. But that’s not exactly correct. With
some notable exceptions, such as super linear speedup, linear speedup is
not possible even if the entire
application ran in parallel. That’s because there is always some
overhead from parallelizing an application, such as scheduling threads
onto separate processors. Therefore, linear speedup is not obtainable.
Here are some of the limitations to linear speedup of parallel code:
Predicting
speedup is important in designing, benchmarking, and testing your
parallel application. Fortunately, there are formulas for calculating
speedup. One such formula is Amdahl’s Law. Gene Amdahl created Amdahl’s
Law in 1967 to calculate maximum speedup for parallel applications.
2.1. Amdahl’s Law
Amdahl’s Law calculates the speedup of parallel code based on three variables:
Duration of running the application on a single-core machine
The percentage of the application that is parallel
The number of processor cores
Here is the formula, which returns the ratio of single-core versus multicore performance.
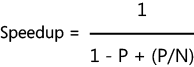
This formula uses the
duration of the application on a single-core machine as the benchmark.
The numerator of the equation represents that base duration, which is
always one. The dynamic portion of the calculation is in the
denominator. The variable P is the percent of the application that runs in parallel, and N is the number of processor cores.
As an example scenario,
suppose you have an application that is 75 percent parallel and runs on a
machine with three processor cores. The first iteration to calculate
Amdahl’s Law is shown below. In the formula, P is .75 (the parallel portion) and N is 3 (the number of cores).
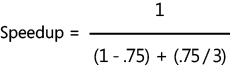
You can reduce that as follows:
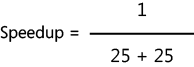
The final result is a speedup of two. Your application will run twice as fast on a three-processor-core machine.

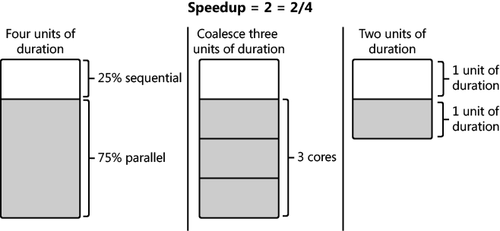
Visualizing speedup can help
you interpret the meaning of Amdahl’s Law. In the following diagram, the
evaluation of speedup is presented as a graph. Duration is represented
as units of equal length. On a single-core machine, application duration
is four units. One of those units
contains code that must execute sequentially. This means that 75
percent of the application can run in parallel. Again, in this scenario,
there are three available processor cores. Therefore, the three
parallel units can be run in parallel and coalesced into a single unit
of duration. As a result, both the sequential and parallel portions of
the application require one unit of duration. So you have a total of two
units of duration—down from the original four—which is a speedup of
two. Therefore, your application runs twice as fast. This confirms the
previous calculation that used Amdahl’s Law.
You can find additional information on Amdahl’s Law at Wikipedia: http://en.wikipedia.org/wiki/Amdahl%27s_Law.
2.2. Gustafson’s Law
John Gustafson and
Edward Barsis introduced Gustafson’s Law in 1988 as a competing
principle to Amdahl’s Law. As demonstrated, Amdahl’s Law predicts
performance as processors are added to the computing environment. This
is called the speedup,
and it represents the performance dividend. In the real world, that
performance dividend is sometimes repurposed. The need for money and
computing power share a common attribute. Both tend to expand to consume
the available resources. For example, an application completes a
particular operation in a fixed duration. The performance dividend could
be used to complete the work more quickly, but it is just as likely
that the performance dividend is simply used to complete more work
within the same fixed duration. When this occurs, the performance
dividend is not passed along to the user. However, the application
accomplishes more work or offers additional features. In this way, you
still receive a significant benefit from a parallel application running
in a multicore environment.
Amdahl’s
Law does not take these real-world considerations into account.
Instead, it assumes a fixed relationship between the parallel and serial
portions of the application. You may have an application that’s split
consistently into a sequential and parallel portion. Amdahl’s Law
maintains these proportions as additional processors are added. The
serial and parallel portions each remain half of the program. But in the
real world, as computing power increases, more work gets completed, so
the relative duration of the sequential portion is reduced. In addition,
Amdahl’s Law does not account for the overhead required to schedule,
manage, and execute parallel tasks. Gustafson’s Law takes both of these
additional factors into account.
Here is the formula to calculate speedup by using Gustafson’s Law.
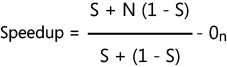
In the above formula, S is the percentage of the serial code in the application, N is the number of processor cores, and On is the overhead from parallelization.